Mi nuevo setup para correr LLMs locales
Seguiré experimentando y reportando mis lecciones por acá; las computadoras son divertidas de nuevo.
Un gran diferenciador en la industria en los siguientes años va a ser la habilidad de correr, optimizar y desplegar LLMs en infraestructura que no tenga acceso a internet.
No quiero decir que esa vaya a ser la norma de cómo se usan estas tecnologías, pero sí un diferenciador de valor muy grande. Empresas que por regulación, por ejemplo, no puedan usar sistemas fuera de su propia infraestructura, van a tener que encontrar la manera de adoptar las tecnologías dentro de un marco de limitantes. Y se van a necesitar personas que sepan hacer eso.
A eso le estoy apostando. Putting my money where my mouth is, estoy estrenando setup:

Toda esta semana he estado explorando las diferentes herramientas para correr LLMs locales. Decidí irme por Ollama, aunque también consideré LM Studio. Nunca fui mucho de usar GUIs, así que realmente el backend de Ollama es más que suficiente para mi caso de uso actual.
Como arnés sigo usando Claude Code. Tengo OpenCode instalado y le he movido un poco, todavía no me siento cómodo y ya traigo memoria muscular con el otro.
Una prueba del rendimiento que traigo:
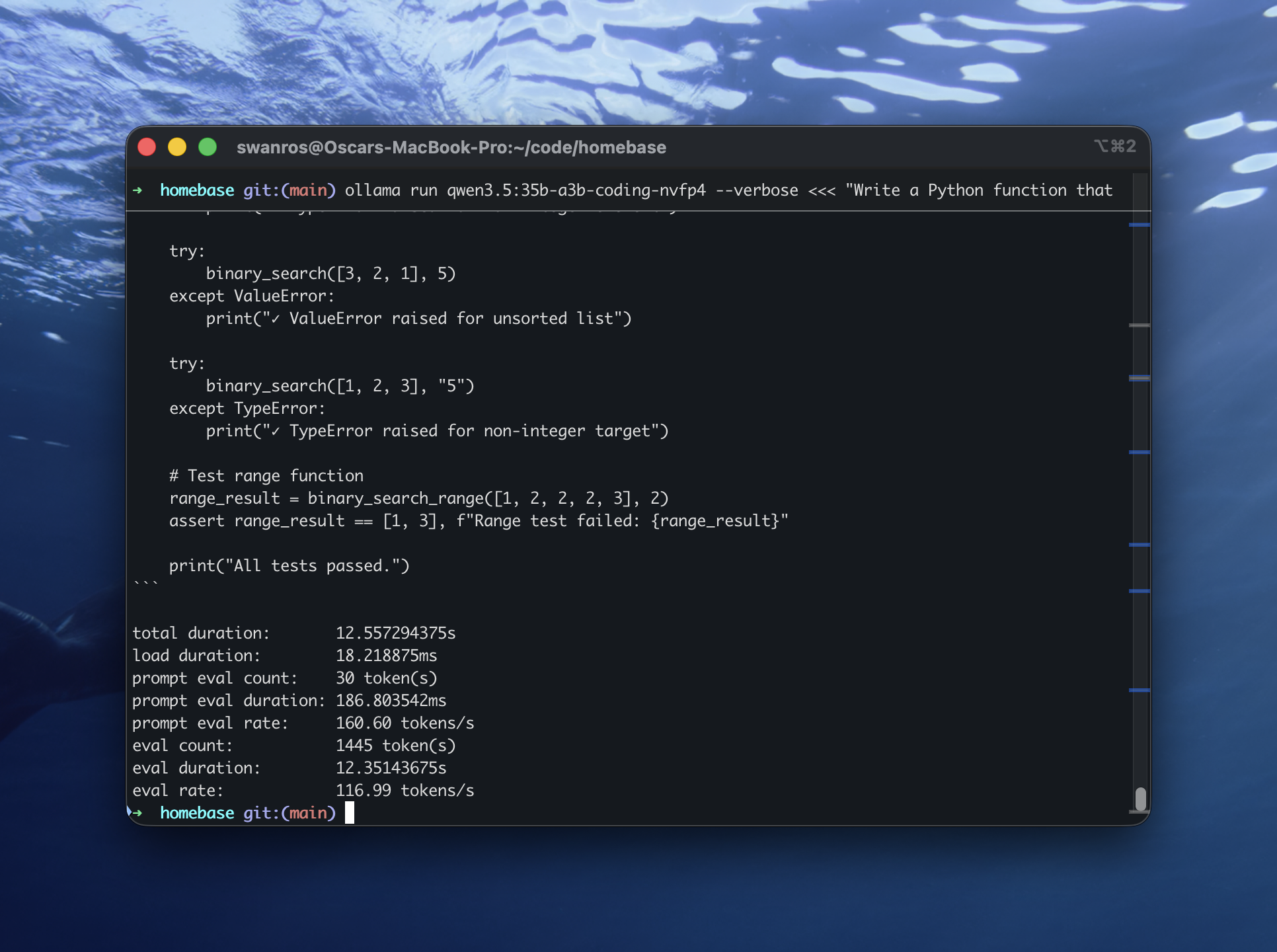
Apenas estoy aprendiendo cómo interpretar estos números, pero a lo que alcanzo a entender, la única manera en que podría sacarle más jugo a este equipo es conectándole un GPU externo.
Ya resolví un par de tareas con el qwen3.5:35b-a3b-coding-nvfp4, y está ooooooooook para tareas mecánicas y muy especialidadas. Funciona rapidísimo, pero no sé si la velocidad de respuesta importa tanto si tiene que intentar varias veces para resolver el problema bien.
Anyway…
Seguiré experimentando y reportando mis lecciones por acá. Las computadoras son divertidas de nuevo.
Cada semana escribo sobre Inteligencia Artificial, Tecnología, Programación e Industria. Recíbelos por correo.
Casi siempre ya sabes la respuesta; lo que falta es alguien que te haga las preguntas incómodas.
Cómo trabajo el coaching 1:1 →
Comentarios
No hay comentarios aun.
Inicia sesión para comentar.